Improve JRuby's hash table performance
The last few weeks I was working on improving JRuby’s hash table implementation. Some of you might remember that with version 2.4, CRuby’s hash table performance improved by around 40% ![]() . Vladimir Makarov achieved this impressive work by implementing open-addressing algorithm. Unfortunately, this change never got implemented in JRuby
. Vladimir Makarov achieved this impressive work by implementing open-addressing algorithm. Unfortunately, this change never got implemented in JRuby ![]() . As I was already contributing smaller features over the last year to JRuby I thought it would be time to contribute something bigger. So here we go!
. As I was already contributing smaller features over the last year to JRuby I thought it would be time to contribute something bigger. So here we go!
The problem!
Hash tables are one of the fastest ![]() and most important data structures in modern programming languages. On average, inserting and searching can be done with
and most important data structures in modern programming languages. On average, inserting and searching can be done with O(1). This is achieved by using the elements key to calculate the index of the element in a hash table. However, if two key’s result with the same index, a collision happens ![]() . Now there are basically two different approaches to resolve this collision: separate chaining and open addressing.
. Now there are basically two different approaches to resolve this collision: separate chaining and open addressing.
So far, JRuby (and CRuby before 2.4) used separate chaining with a linked list. It is important to know that Ruby keeps the insertion order of the elements in the hash (this is not a requirement of a hash table but a neat feature of Ruby). With separate chaining, every element gets inserted into a bin array according to it’s key. If the bin is already occupied by another element, it starts to build a single linked list. For iterating over the hash by insertion order, it maintains a head reference and additionally previous and next references on every element. Therefore JRuby instantiates for every element a RubyHashEntry object. The architecture looks basically like this:

Before we can optimize JRuby’s hash, we first need to understand the disadvantages of the current implementation ![]() . Modern computer architectures take advantage of locality of reference which basically means: if a particular memory location is accessed it is very likely that nearby memory locations will be accessed in the near future as well. For instance, when you access the first element of an array most of the time you also access the second element (and so on). Every time an element is now read by the CPU, it also reads the values nearby and stores them in the CPU’s cache to make future reads a lot faster
. Modern computer architectures take advantage of locality of reference which basically means: if a particular memory location is accessed it is very likely that nearby memory locations will be accessed in the near future as well. For instance, when you access the first element of an array most of the time you also access the second element (and so on). Every time an element is now read by the CPU, it also reads the values nearby and stores them in the CPU’s cache to make future reads a lot faster ![]() . And as it turns out, linked lists (and our current hash table implementation) do not perform very well in terms of cache locality
. And as it turns out, linked lists (and our current hash table implementation) do not perform very well in terms of cache locality ![]() .
.
To make the most out of cache locality, objects should be as small as possible. With our current implementation, we need to store additional to the key and value of the element three references (for previous & next element and for potential collisions) which increases the size of the objects quite a bit. Furthermore the elements in linked lists are distributed in memory and therefore the probability that the next element is already loaded in the CPU’s cache is low. In order to improve our performance, we need to decrease the size of the elements as most as possible as well as store the elements close together to avoid jumping in memory.
The idea
A different approach to implement collision resolution is open addressing. Instead of creating a linked list when a collision happens, in open addressing the element just gets inserted in a different still empty bucket, for instance just the next empty one (linear probing). This has the big advantage that it is not necessary to store references anymore and also the elements are stored close together in an array instead of a linked list. As we don’t need to store the references anymore, we also removed the RubyHashEntry objects completely ![]() . We now just store the key and values without a wrapper object which decreases the number of objects which need to get allocated as well as the overall size tremendously. To maintain the insertion order, we store the actual key and value objects by insertion in one array and have another array for the indexes. Additionally we have a third array to cache the hash values. This is necessary because the hash values are integers and therefore we would need to convert them to Integer objects if we want to store them together with the key and values. The new architecture basically looks like this:
. We now just store the key and values without a wrapper object which decreases the number of objects which need to get allocated as well as the overall size tremendously. To maintain the insertion order, we store the actual key and value objects by insertion in one array and have another array for the indexes. Additionally we have a third array to cache the hash values. This is necessary because the hash values are integers and therefore we would need to convert them to Integer objects if we want to store them together with the key and values. The new architecture basically looks like this:

This was just a short overview but I highly recommend to read the articles by Vladimir Makarov (who did the implementation in CRuby) and Jonan Scheffler for more information about this topic.
How hard can it be?
Although I already contribute to different open source projects since a few years, this was one of the biggest patches I have submitted so far. It was not only one of the biggest contributions, it was also one the contributions I learned the most about open source and it’s community ![]() .
.
As I helped to implement missing 2.5 features in JRuby beginning of the year, I already knew some of the core contributor as well as how contributing to JRuby in general works. While implementing features for 2.5 support, I also discovered and fixed some issues in the RubyHash class. At some point, Charles Nutter pointed me to issue #4708 which was about a new hash implementation. After investigating and researching a little bit, I started implementing and immediately got frustrated. The RubyHash class has ~2900 LOC and is so fundamental to JRuby that if you mess something up, you end up with a not even starting or broken Ruby interpreter. At some point, I thought everything was working just to figure out that it was not possible to require gems anymore ![]() . After some hours debugging I finally had something working but the benchmarks were not looking very promising. I realized I was in a dead end
. After some hours debugging I finally had something working but the benchmarks were not looking very promising. I realized I was in a dead end ![]() !
!
So beginning of June I was in contact with Charlie again and asked for some directions and he suggested to open a pull request. And honestly I didn’t like this idea in the beginning as the code was really ugly (I didn’t program Java in years) and I also didn’t know how much time ![]() and motivation
and motivation ![]() I will have the next weeks to finish the PR. Looking back, I think this was one of the reasons it was eventually a success. Almost immediately after I opened the PR, several JRuby contributors commented on the PR and in IRC to give me feedback and ideas. For instance it was Marcin Mielżyński’s idea to get rid of the
I will have the next weeks to finish the PR. Looking back, I think this was one of the reasons it was eventually a success. Almost immediately after I opened the PR, several JRuby contributors commented on the PR and in IRC to give me feedback and ideas. For instance it was Marcin Mielżyński’s idea to get rid of the RubyHashEntry objects and pack everything into one array. This approach significantly decreased the number of object allocations and improved the performance eventually. Getting as early as possible feedback, even if you only have a prototype, is fundamental!
After finishing the prototype and the performance were improving, the last step before merging was to fix all failing tests. And as Hash tables are so fundamental in Ruby, consequentially this class is extensively tested. Not only dedicated tests exist but this class also gets tested indirectly by many many other tests. This is a great thing but caused a lot frustration for me as there were hundreds of tests failing in the beginning and I didn’t even know were to start! However, as I’m relatively new to the huge JRuby codebase, I knew automated tests were my safety net I needed to rely on. And after the first frustration was gone I realized I need to do small steps, fixing test by test, stage by stage. You probably won’t believe me but simple ‘off by one’ errors caused the most frustration (e.g. not moving correctly start / end pointers after deleting the first / last element were driving me nuts) ![]() .
.

When working on such a performance improvement, it is very important to constantly measure if the performance actually improves. Therefore Takashi Kokubun developed the awesome benchmark-driver for the work on Ruby 3x3 (Ruby 3 should be 3 times faster than Ruby 2). Although Ruby’s standard library already comes with a handy benchmark class, benchmark-driver offers some more advanced features. The most awesome feature is that you can easily compare different Ruby binaries by just providing the binary or using rbenv. Furthermore it is possible to generate the output in many different formats including markdown and even rendering a graph. And while measuring the performance of my code, I also discovered and fixed several bugs in benchmark-driver (#40, #42, #43) and JRuby (#5297) itself.
Many people use rvm or rbenv to install different Ruby’s on their machine. However, most probably don’t know that you can install development versions of Ruby with it and use it in your CI setup! This is great to discover deprecation and regression issues before the new Ruby is even released. And also to provide valuable feedback to Ruby developers. For instance, Rails does it. This made it possible that we discovered several bugs in this refactoring (#5280, #5304) and for instance also in bundler (#6669).
The last few years I mostly programmed in Ruby professionally. Because of that, I did not use much static typing. And when I started to contribute to JRuby it felt annoying to always specify the type. However, the hash refactoring was more than 600 LOC and doing such a refactoring in a dynamic language without compiler would have been a lot more difficult. I don’t remember how often I found trivial bugs already at compile time. So in the end, I really embraced static typing again ![]() .
.
Last but not least I want to talk about one challenge most open source projects face: Attracting and integrating new contributors. Open source contributions should be a win-win situation, for the open source project and the contributor. The open source project obviously ‘wins’ the code contribution (of course with the burden of maintaining it in the long run). And for the contributor there can be many different incentives like learning a new technology, facing a nasty bug in your favorite library, getting attribution or just for the sake of fun. For me, contributing to open source is mostly a mix of learning and fun. And since my first pull request to JRuby, I learned a ton! I brushed up my Java knowledge, looked into the CRuby code, wrote C / Java extensions, discovered methods in Ruby’s standard library I have never used before and submitted patches to several other Ruby projects to just name a few. As open source is about sharing and my memory is quite bad, this blog article is also an attempt to share what I learned the last two months ![]() .
.
But what is the result?
First of all, my code is already merged upstream and will probably be included in the next JRuby release 9.2.1.0.
And after mostly talking about the theory and what I learned by implementing all this it’s time now to show the actual results. I compared setting and fetching keys in hashes of different sizes. I will only discuss a few examples but you can see a more detailed list of my benchmark results in this repository.
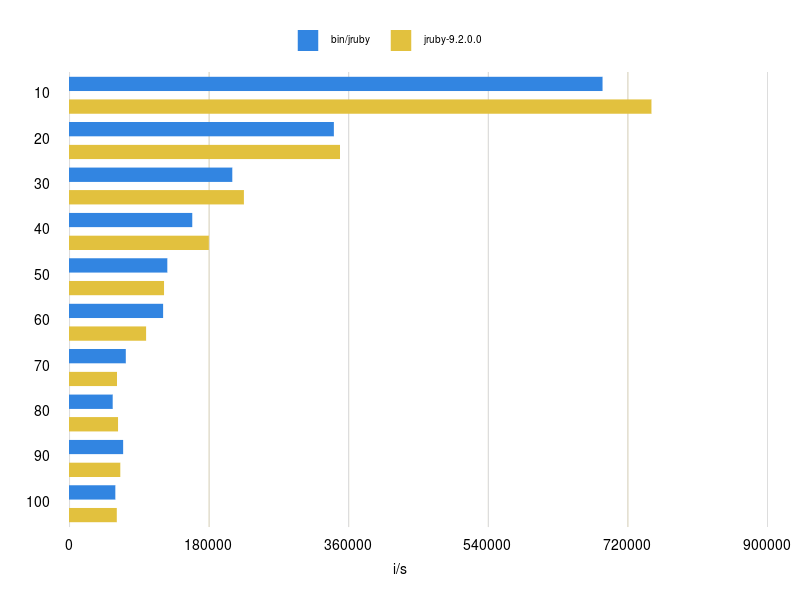
Set 100 strings (blue open addressing)
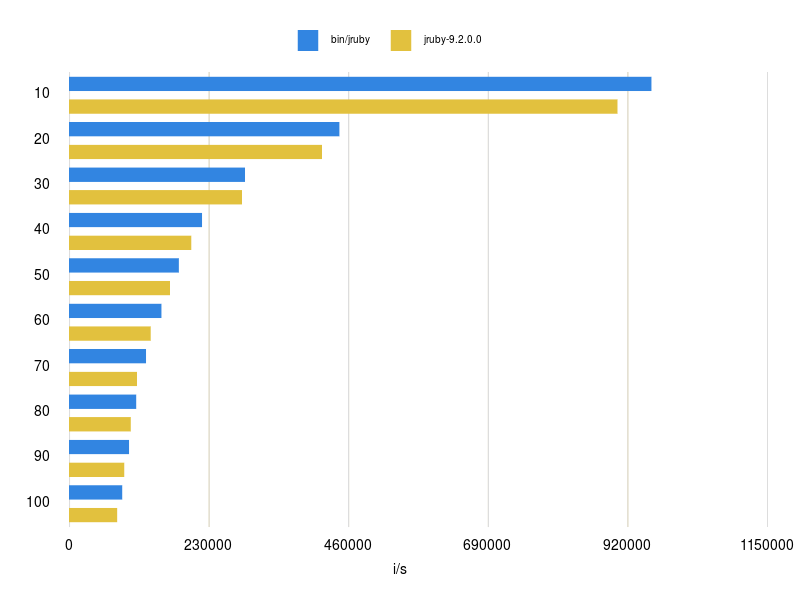
Fetch 100 strings (blue open addressing)
The first graph shows setting 10 to 100 keys into a hash table and the performance is very close with the old implementation but sometimes a little slower (a longer bar is better as it means more iterations per seconds). The reason for this is that the new implementation needs to resize the hash more often (8 -> 32 -> 128). The old implementation only needs to resize once and also the resize does not ‘hurt’ much as there are not many keys in the hash. Fetching keys is around ~10 % faster for the new implementation for obvious reasons. Setting and fetching 1-10 keys is also around ~10-20 % faster, have a look at this repository for more details.
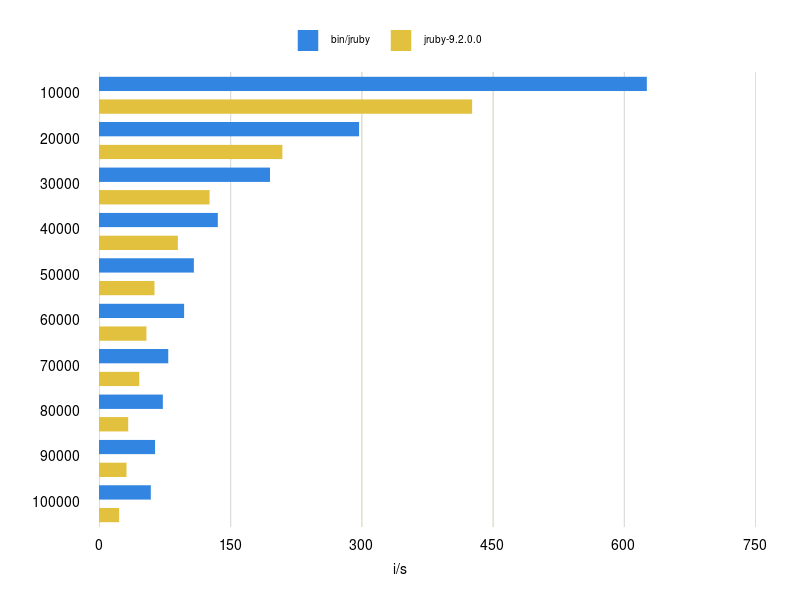
Set 100,000 strings (blue open addressing)
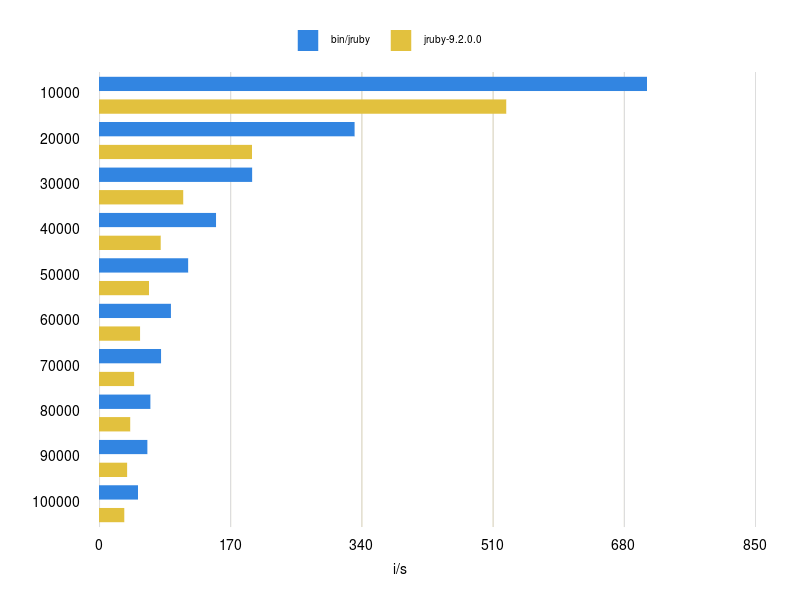
Fetch 100,000 strings (blue open addressing)
However, it’s getting really interesting for large hashes with more than 10,000 keys. As you can see in the graphs, the new implementation is sometimes more than 2 times faster. Compared to the small hashes were setting was around the same performance (or sometimes a little slower) for large hashes it is a lot faster now. Resizing larger hashes with closed addressing needs to constantly jump in memory which slows it down significantly. I also tested the performance for hashes between 100 and 10.000 keys and the results can also be found in this repository.
Charlie also did some benchmarks which indicate that this patch will also help to improve the performance on Graal JIT in the future. And I still have some refactorings and improvements in my mind. We will see!

Acknowledgments
This patch would not have been possible without the help from the JRuby core team including Charles Nutter, Thomas Enebo, Karol Bucek, Marcin Mielżyński and the excellent work by Vladimir Makarov on CRuby. Thanks also to the JRuby community for patiently testing and reporting issues.