What I learned from contributing to JRuby
Last week, JRuby 9.2.0.0 with Ruby 2.5 support got released ![]() .
And with it, some code from me as well.
This is what I learned from my contributions.
.
And with it, some code from me as well.
This is what I learned from my contributions.
Hash & Set
According to the Ruby documentation, a set is a collection of unordered values with no duplicates.
In Ruby 2.5, the set class got a reset method which comes handy if you change an object after inserting it to a set.
To better understand the issue, look at the following code (works only with Ruby 2.5):
require 'set'
a = [1, 2]
b = [1]
set = Set.new([a, b])
# Changing b to be a duplicate of a
b << 2
puts set # => <Set: {[1, 2], [1, 2]}>
# Reset to remove potential duplicates from the set
set.reset
puts set # => <Set: {[1, 2]}>
To understand in detail what the reset method does, we need to look into how set is implemented.
Looking back at the definition, the important part is no duplicates!
To achieve this, set uses a hash internally to store its data.
Hashes are key-value data structures which by definition can not have duplicate keys.
This makes adding and searching elements very efficient (O(1) in average case).
While the hash class already had a rehash method which rebuilds the hash, set lacked a similar method.
With this knowledge, it was easy to implement the reset method in JRuby by simply calling rehash on the internally stored hash. The full implementation can be found here.
While implementing the reset method, I found out that the rehash function had a bug and did not properly rebuild the hash. To fix this bug, I needed dive into how hashes are implemented.
In JRuby, hashes are implemented by separate chaining with linked lists for collision resolution. To insert an element, a hash function is used to calculate the index of the element. As example we will use the modulo operation as our hash function. If two keys have the same index value, a collision happens which we need to resolve. With seperate chaining by linked lists, we simply store the reference of the new element in the previous element. See the following illustration for better understanding:
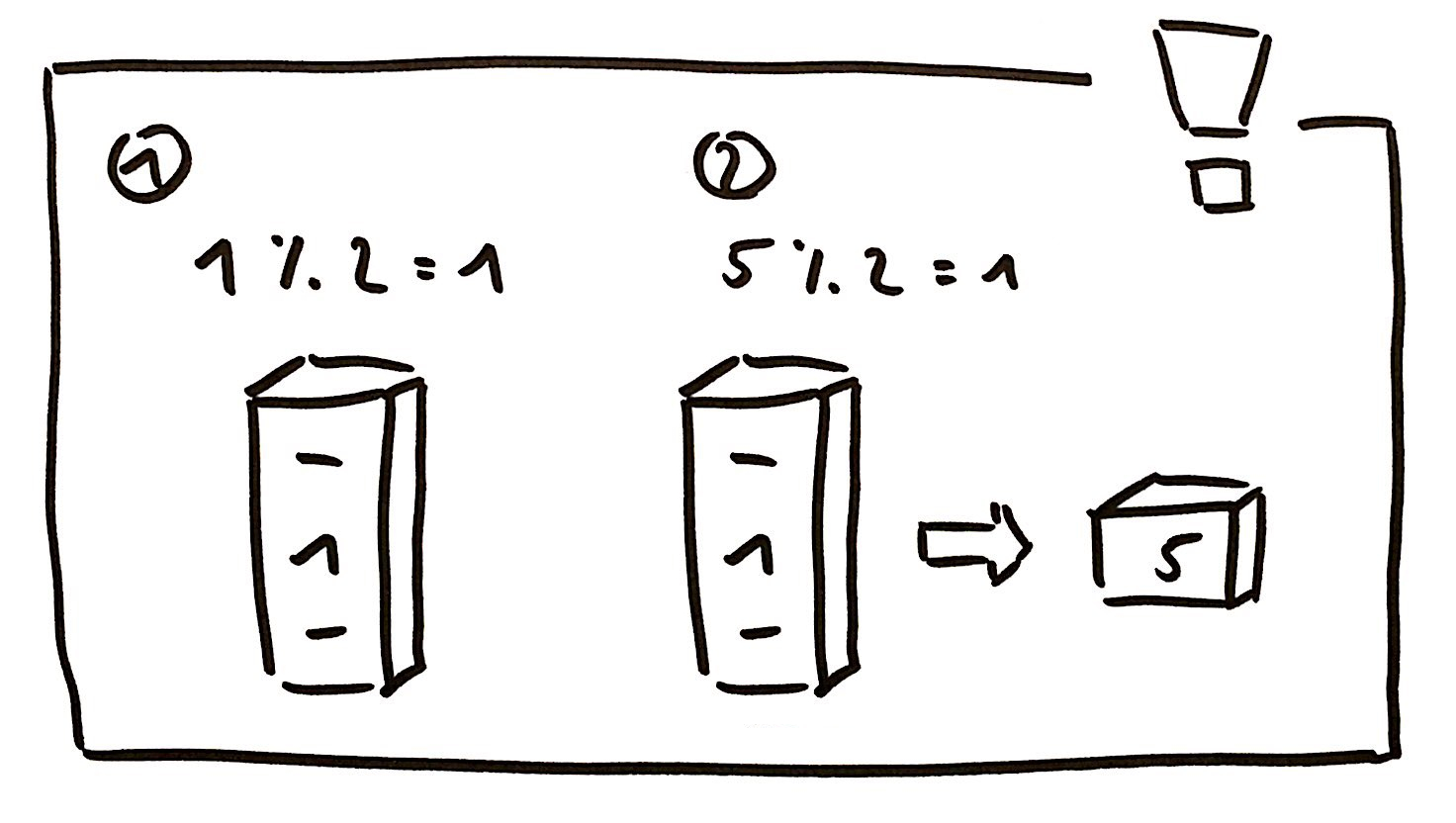
We have an array with the length of three.
The first element we add is one which gets stored at position one (1 % 2 = 1).
As second element we want to add five which also has the position one (5 % 2 = 1).
However, the first position is already occopied and we need to resolve this collision.
With the separate chaining, we just store a reference to element five in element one.
Easy-peasy, right?
Unfortunately, the rehash function did just ignore duplicate keys and inserted them again. The fix was to cleanup the references of the list.
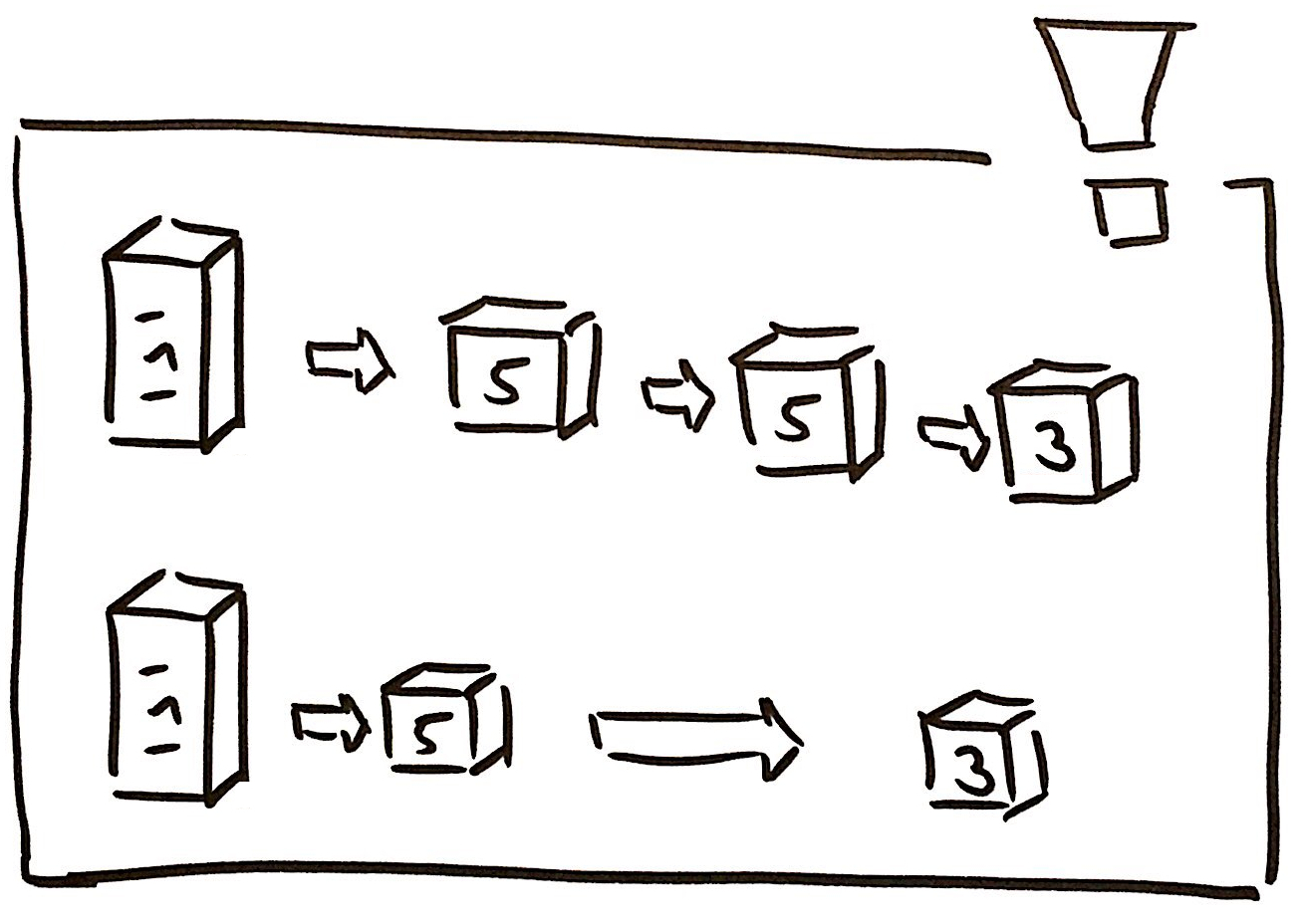
In the image you see that five is two times in the hash. However, to remove five, we also need to change the reference of the first five to the next element. This is what we did in PR#4961.
Hash also got the new method slice, which makes it possible to only select matching keys from a hash. This was already possible in Rails and finally it is now part of Ruby core. The implementation in JRuby can be found here.
Altough I learned how sets and hashes are implemented back at university, it was really nice to dive into it again and see how this works in JRuby ![]() .
.
String
The String class also got some new methods with the new Ruby release.
Some of you may know that -'foo' is syntactic sugar for 'foo'.freeze.
From Ruby 2.5 on, the @- method also deduplicates strings which helps to reduce memory usage.
There is also a very interesting post on the ruby-talk mailinglist about this topic which I recommend to read.
Look at this pull request if you want to know the implementation details.
Very useful is also that String#start_with? now supports regular expressions.
So for instance start_with?(/fo*bar/) will now match foobar and fobar.
Pretty neat, isn’t it?
Here is how we implemented it.
Do you sometimes need to remove the beginning or ending of a string?
Unfortuntely, there was no built in way to do so until Ruby 2.5.
However, Ruby 2.5. comes now with delete_prefix and delete_suffix methods (and corresponding bang methods) which makes this task super easy.
The JRuby implementation can be found here and here.
This was just a wrap up of new stuff I found interesting.
If you want to know what else changed in Ruby 2.5, have a look at the official release notes of MRI or JRuby.
A full list of my contributions to JRuby can be found here ![]() .
.
Acknowledgments
When I submitted my first PR to JRuby, I was a little bit intimidated and expected that reviewing and merging it will take quite some time. But as it turned out, despite the JRuby core members are quite busy, they were super fast and helpful with reviewing my PRs. I would like to especially thank Charles Nutter, Thomas Enebo and Karol Bucek for their help and feedback, I really learned a lot from my contributions to JRuby.